set.seed(0)17 Dynamic Network Modeling in EpiModel
Tutorial by Martina Morris, Steven M. Goodreau and Samuel M. Jenness. Based on packages developed by the statnet Development Team.
17.1 Set-up
Set the seed for reproducibility, if you wish:
and load the EpiModel package, which automatically loads all of the other statnet packages we need:
library(EpiModel)17.2 Scenario 1: MSM Networks
Imagine that we wish to model networks of “men who have sex with men” (MSM) in steady partnerships, with the ultimate goal of exploring HIV dynamics in this population.
We collect egocentric data that suggest that:
- The average MSM is in 0.4 ongoing partnerships
- The average ongoing partnership lasts 90 time steps.
We wish to start simply by just generating a dynamic network that retains these two features on average over time, and is otherwise random.
17.2.1 Model Parameterization
We begin by creating an empty network (i.e. a network with no edges) but with nodes. For now, we will make all the nodes the same, i.e. without any individual nodal attributes. Let us say that we wish to do our simulations on a dynamic network with 100 nodes.
net1 <- network_initialize(100)Now, we need to identify the terms for our relational model. This is easy: since we are considering a purely homogeneous process right now, the only term in the formation model is ~edges. Indeed, dissolution is also purely homogeneous, so it is also ~edges.
Now, we need to calculate our target statistic for the formation model, i.e. the number of edges we expect in the network on average. The answer is:
\[\frac{(100)(0.4)}{2} = 20\]
Why did we divide by two?
Now, to estimate the coefficients for our model–both formation and dissolution–we turn to EpiModel, and specifically, the netest function.
We will estimate our formation and dissolution models sequentially; first the dissolution model, and then the formation model conditional on the dissolution model. To do the former, we use the dissolution.coefs function, passing in the dissolution model terms and the durations associated with it. Note that, we need a way to let the formation estimation know that the dissolution model will consist of a fixed parameter rather than one to be estimated. In EpiModel (and in R more generally) this is done by placing a model term inside the function offset().
coef.diss.1 <- dissolution_coefs(~offset(edges), 90)
coef.diss.1Dissolution Coefficients
=======================
Dissolution Model: ~offset(edges)
Target Statistics: 90
Crude Coefficient: 4.488636
Mortality/Exit Rate: 0
Adjusted Coefficient: 4.488636For now, do not worry about the adjusted coefficient and the death rate; we will return to these down the road once we’ve added vital dynamics to our models. But notice that the dissolution coefficient that is returned by this function equals \(ln(90-1)\).
17.2.2 Model Fitting
Now we fit our formation model conditional on this:
fit1 <- netest(net1,
formation = ~edges,
target.stats = 20,
coef.diss = coef.diss.1)Querying the contents of fit1 with the summary command provides us an overview of the model fit:
summary(fit1)Call:
ergm(formula = formation.nw, constraints = constraints, offset.coef = coef.form,
target.stats = target.stats, eval.loglik = FALSE, control = set.control.ergm,
verbose = verbose)
Maximum Likelihood Results:
Estimate Std. Error MCMC % z value Pr(>|z|)
edges -5.507 0.224 0 -24.58 <1e-04 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Log-likelihood was not estimated for this fit. To get deviances, AIC, and/or BIC, use ‘*fit* <-logLik(*fit*, add=TRUE)’ to add it to the object or rerun this function with eval.loglik=TRUE.
Dissolution Coefficients
=======================
Dissolution Model: ~offset(edges)
Target Statistics: 90
Crude Coefficient: 4.488636
Mortality/Exit Rate: 0
Adjusted Coefficient: 4.488636But of course what we really want to know is whether a dynamic network simulated from this model retains the cross-sectional structure and relational durations that we asked it to. To check this, we use the netdx (“net diagnostics”) command to both conduct the simulation and compile the results for comparison to our expectations. We will include a flag to keep the “timed edgelist”, a means for storing data on every edge in the network over time in a data.frame. This is FALSE by default since it can become very large for long simulations, and is not generally needed when only looking to confirm that the sufficient statistics are matched. Here it is worth getting a sense of its contents.
17.2.3 Model Simulation
sim1 <- netdx(fit1, nsteps = 1000, nsims = 10,
keep.tedgelist = TRUE)
Network Diagnostics
-----------------------
- Simulating 10 networks
|**********|
- Calculating formation statisticsDoes our formation model lead to a dynamic network that stochastically captures our target statistic of 20 edges in the cross-section? We can get an overview by printing the simulated object:
sim1EpiModel Network Diagnostics
=======================
Diagnostic Method: Dynamic
Simulations: 10
Time Steps per Sim: 1000
Formation Diagnostics
-----------------------
Target Sim Mean Pct Diff Sim SE Z Score SD(Sim Means) SD(Statistic)
edges 20 19.786 -1.068 0.483 -0.443 1.803 4.339
Duration Diagnostics
-----------------------
Target Sim Mean Pct Diff Sim SE Z Score SD(Sim Means) SD(Statistic)
edges 90 89.699 -0.334 2.452 -0.123 8.994 21.571
Dissolution Diagnostics
-----------------------
Target Sim Mean Pct Diff Sim SE Z Score SD(Sim Means) SD(Statistic)
edges 0.011 0.011 0.309 0 0.14 0.001 0.024And we can get a visual sense of the network structure over time with:
plot(sim1, type = "formation")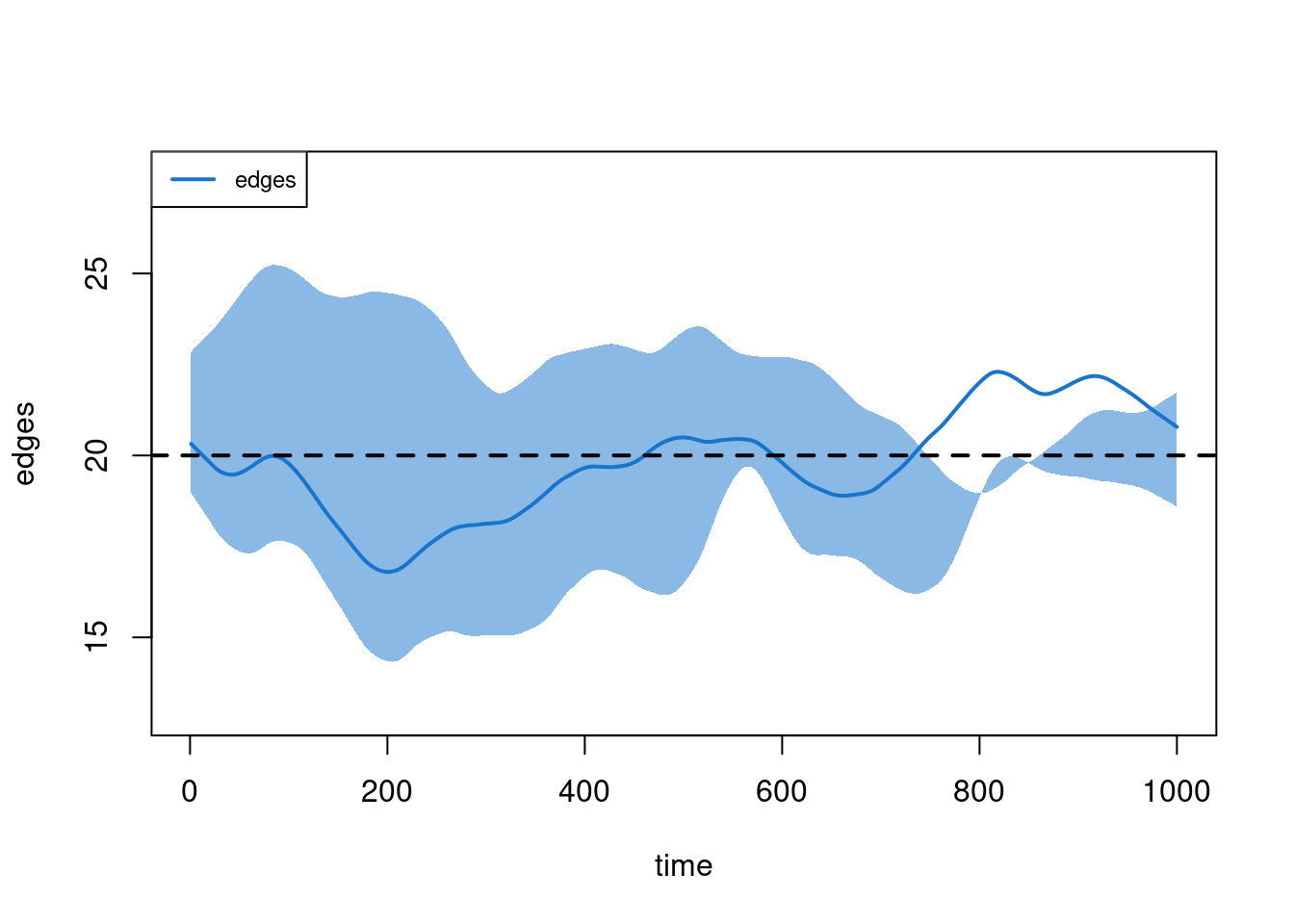
And of the relational durations with:
plot(sim1, type = "duration")
This looks good. But ponder for a moment: what might it mean when we see that the ties at, say, timestep 5 have an average duration of about 90 timesteps? (Think about this before reading ahead).
In order to calculate a mean that lets the user know whether or not the model is working as expected, the print and plot commands automatically impute starting dates for ties that exist at the start of the diagnostic simulation. It does so based on the memoryless properties of the geometric distribution that underlies the ~edges dissolution model. If you want to see the data without this imputation, type:
plot(sim1, type = "duration", duration.imputed = FALSE)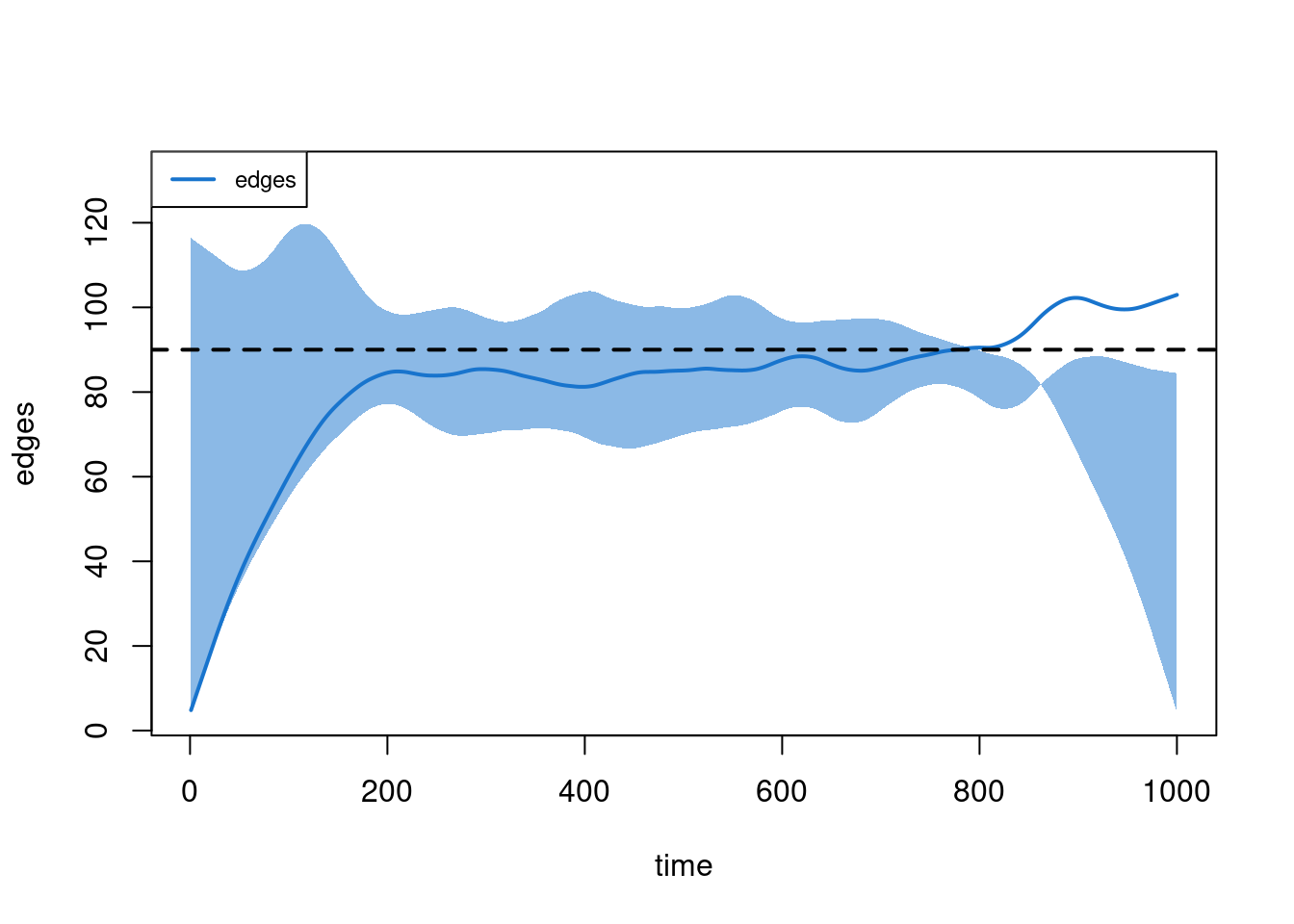
An equivalent way to examine the dissolution model that is not subject to this ramping up is with:
plot(sim1, type = "dissolution")
Which corresponds to the Pct Edges Diss line in the summary printout above.
Finally, we look at the first few rows of the timed edgelist, out of curiosity:
tel <- as.data.frame(sim1, sim = 1)
head(tel, 25) onset terminus tail head onset.censored terminus.censored duration edge.id
1 0 119 3 12 TRUE FALSE 119 1
2 0 17 6 37 TRUE FALSE 17 2
3 0 19 7 37 TRUE FALSE 19 3
4 0 53 7 61 TRUE FALSE 53 4
5 0 126 8 44 TRUE FALSE 126 5
6 0 7 11 12 TRUE FALSE 7 6
7 0 56 13 84 TRUE FALSE 56 7
8 0 116 15 36 TRUE FALSE 116 8
9 0 90 15 50 TRUE FALSE 90 9
10 0 101 19 49 TRUE FALSE 101 10
11 0 32 23 89 TRUE FALSE 32 11
12 0 184 24 27 TRUE FALSE 184 12
13 0 57 27 33 TRUE FALSE 57 13
14 295 330 27 33 FALSE FALSE 35 13
15 0 18 45 85 TRUE FALSE 18 14
16 0 48 47 53 TRUE FALSE 48 15
17 0 174 53 62 TRUE FALSE 174 16
18 0 31 59 67 TRUE FALSE 31 17
19 0 65 59 68 TRUE FALSE 65 18
20 0 224 70 86 TRUE FALSE 224 19
21 0 21 78 95 TRUE FALSE 21 20
22 0 24 80 87 TRUE FALSE 24 21
23 0 28 80 97 TRUE FALSE 28 22
24 3 15 8 9 FALSE FALSE 12 23
25 5 80 49 67 FALSE FALSE 75 24One can choose to explore this further in a host of ways. Can you identify what each query is doing?
hist(tel$duration)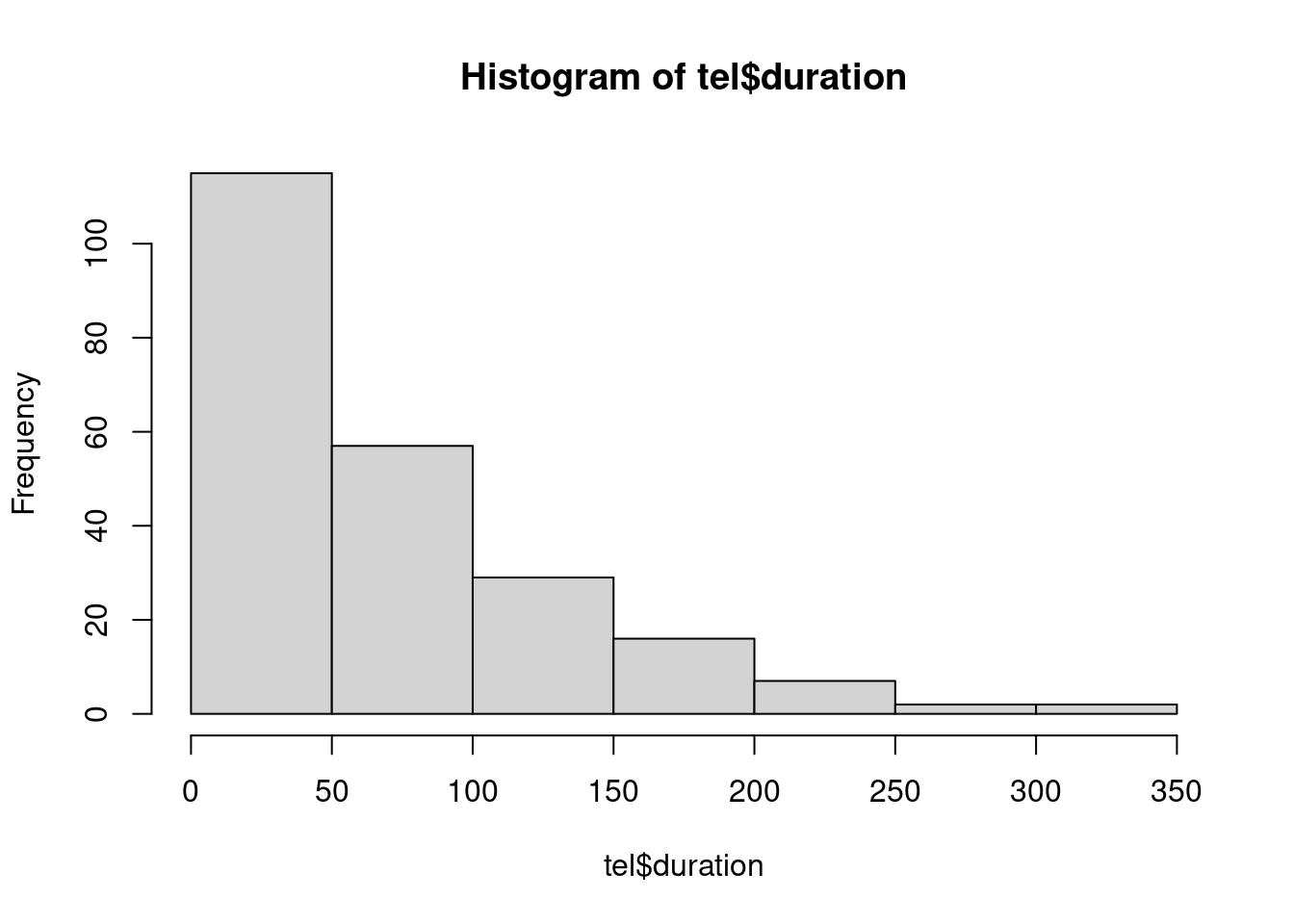
sum(tel$terminus.censored == TRUE)[1] 20plot(tel$onset, tel$terminus)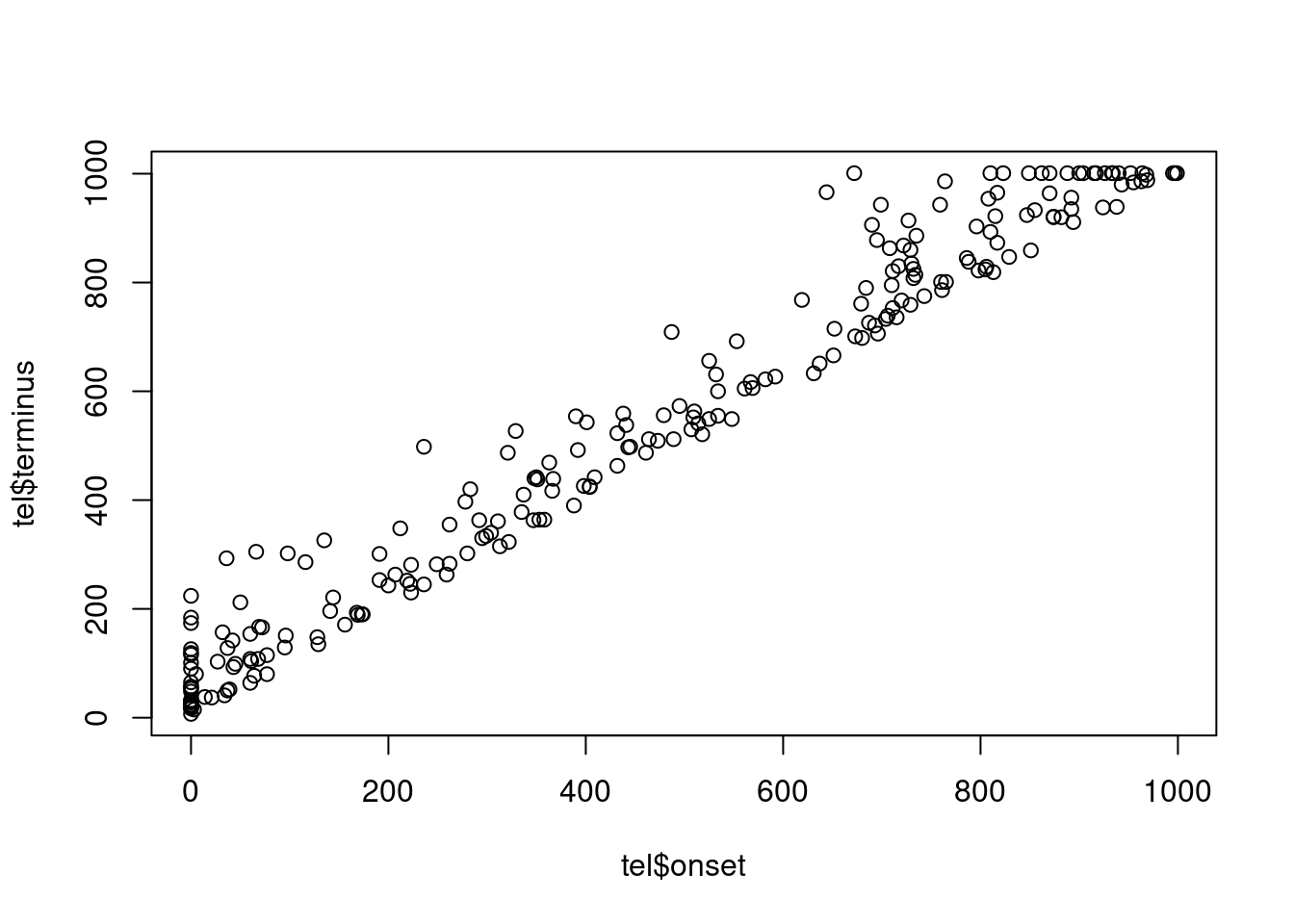
table(c(tel$head,tel$tail))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
1 4 6 2 2 3 10 8 5 3 6 4 7 3 8 3 4 2 4 3
21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
4 8 3 4 2 9 7 3 4 4 2 4 7 5 5 5 5 6 4 3
41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
5 4 6 9 4 4 3 4 8 6 8 4 9 4 5 8 7 3 7 3
61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80
6 4 5 3 7 4 7 7 4 5 3 3 2 5 7 2 4 5 3 3
81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
1 6 2 9 4 5 3 5 2 4 4 3 1 3 5 4 3 1 6 3 hist(table(c(tel$head,tel$tail)))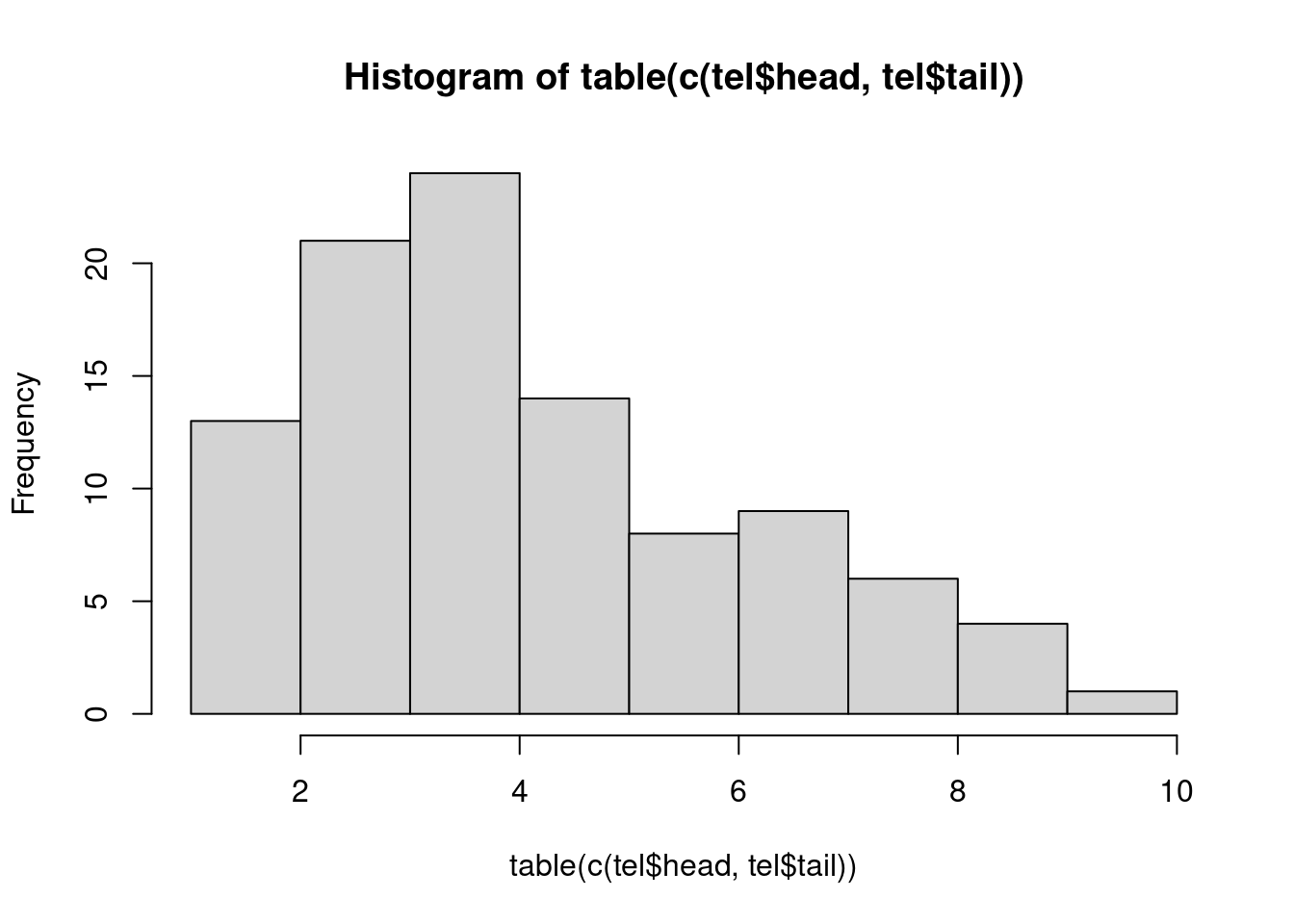
You may also wish to examine the network at specific time points, or visualize the entire network with a dynamic plot. These features are not available for the netdx command specifically, but we will be able to use them tomorrow when we begin with epidemic simulation on the networks.
17.3 Scenario 2: Modifying Network Size
What if instead we had done a network of 1000, but with the same observed data? What values would we need to change in our calls? (Note: from now on, we will simplify our calls somewhat and save ourselves a step by nesting the dissolution call directly inside the formation one.)
net2 <- network_initialize(1000)
fit2 <- netest(net2,
formation = ~edges,
target.stats = 200,
coef.diss = dissolution_coefs(~offset(edges), 90))
sim2 <- netdx(fit2, nsteps = 1000, nsims = 10, keep.tedgelist = TRUE)
Network Diagnostics
-----------------------
- Simulating 10 networks
|**********|
- Calculating formation statisticsplot(sim2, type = "formation")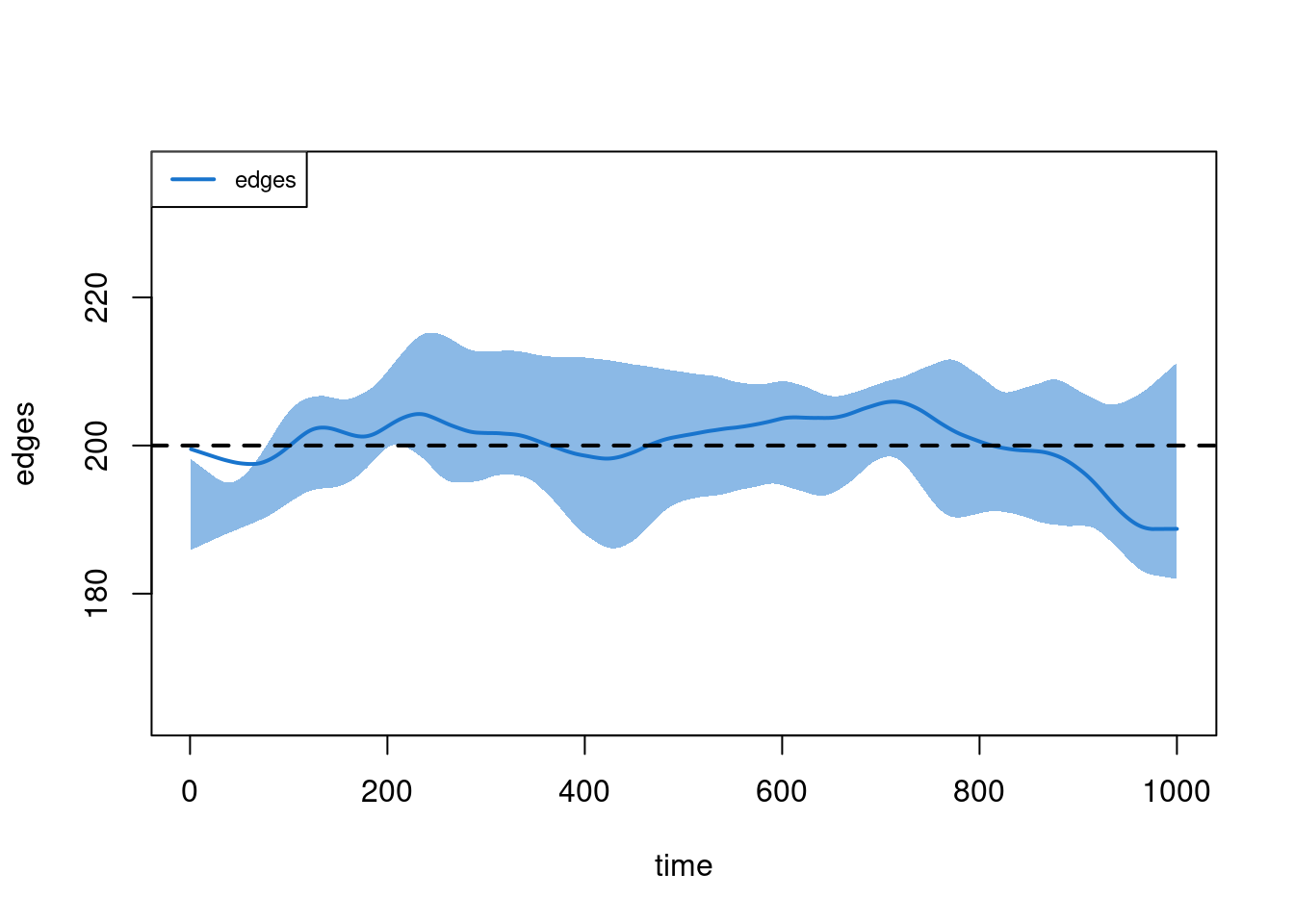
plot(sim2, type = "duration")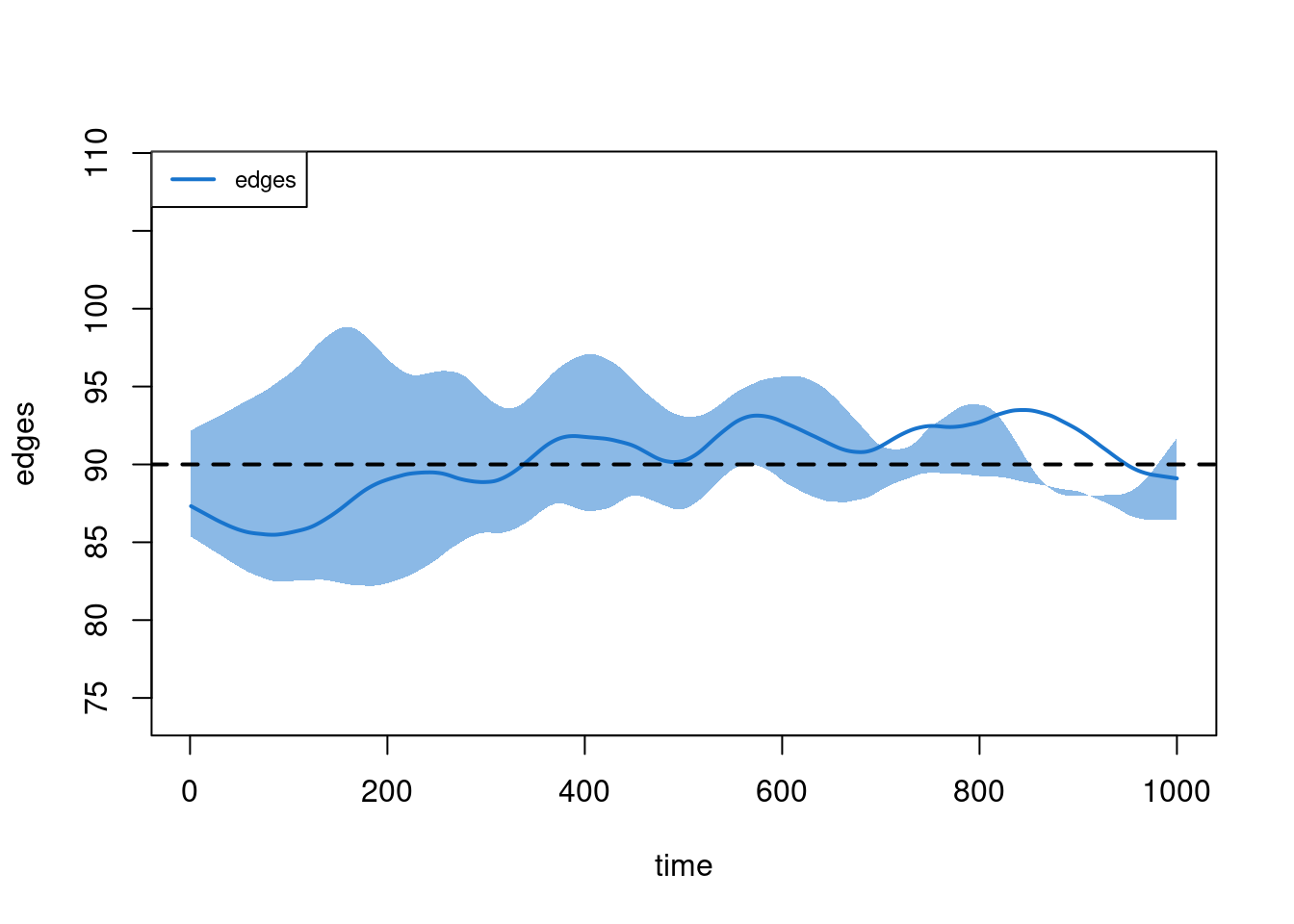
plot(sim2, type = "dissolution")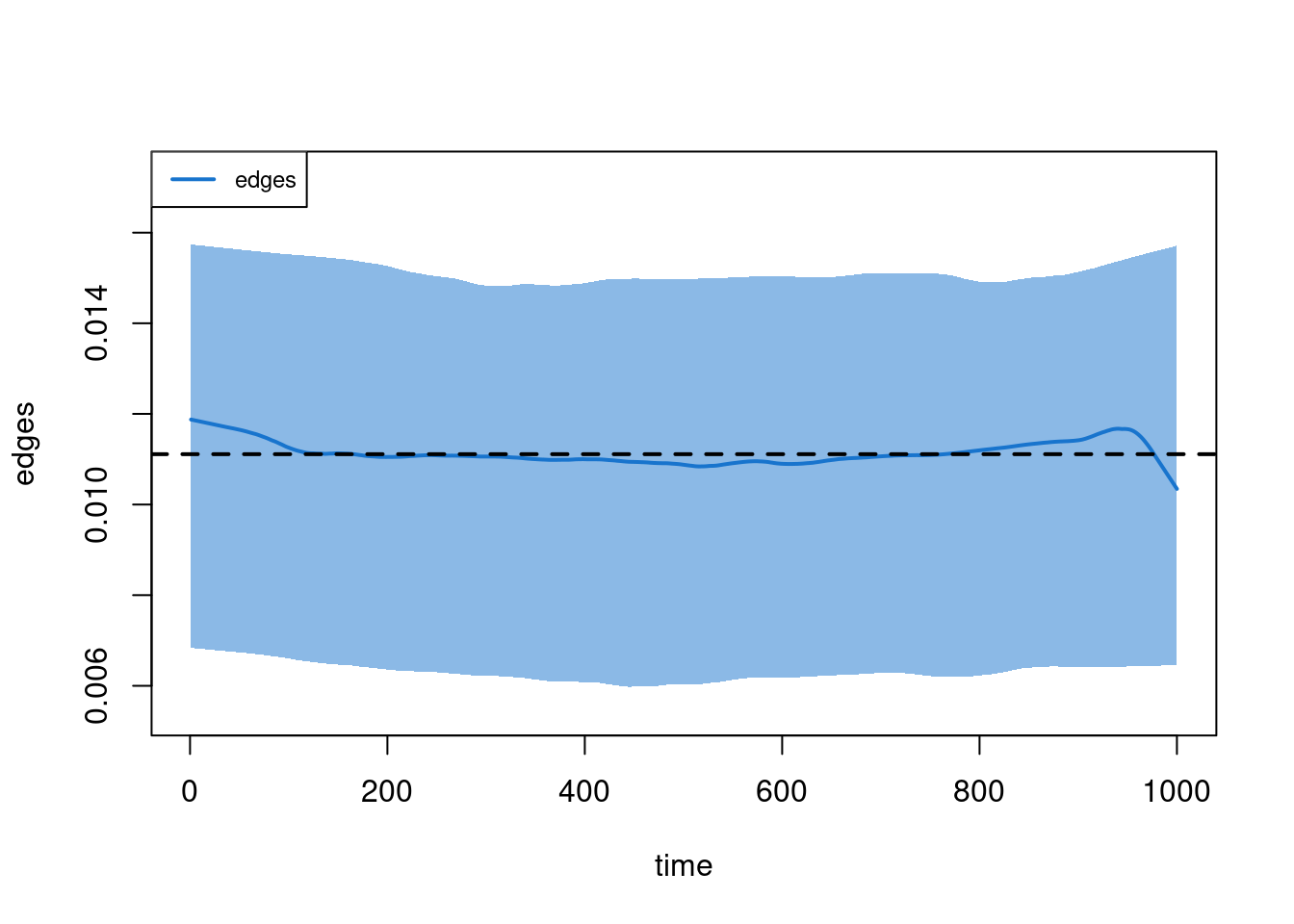
Lesson learned from Scenario 2: remember to change your target stats when you change your network size. Better yet, make your target stats functions of your network size instead of fixed values! That is, something like:
# Do not run
nnodes <- 1000
meandeg <- 0.4
net2 <- network_initialize(nnodes)
fit2 <- netest(net2,
formation = ~edges,
target.stats = nnodes*meandeg/2,
coef.diss = dissolution_coefs(~offset(edges), 90))17.4 Scenario 3: Adding ERGM Terms
Now we want to ramp up the complexity of our model a bit. For example, let us imagine we wish to control aspects of the momentary degree distribution, as well as race mixing. Conveniently, we happen to be working in a community in which 50% of MSM are Black and 50% are White. And our egocentric partnership data say:
There are no significant differences in the distribution of momentary degree (the number of ongoing partnerships at one point in time) reported by Black vs. White men. The mean is 0.90, and the overall distribution is:
36% degree 0
46% degree 1
18% degree 2+
83.3% (i.e. 5/6) of relationships are racially homogeneous
We also have data (from these same men, or elsewhere) that tell us that the mean duration for a racially homogeneous relationship is 100 weeks, while for a racially mixed one it is 200 weeks. Perhaps this is because the social pressure against cross-race ties makes it such that those who are willing to enter them are a select group more committed to their relationships.
17.4.1 Model Parameterization
The size of the network we wish to simulate is again arbitrary; let us pick 250. Our first step, then, is to create a 250-node undirected network, and assign the first half of the nodes to race “B” and the second to race “W”.
n <- 250
net3 <- network_initialize(n)
net3 <- set_vertex_attribute(net3, "race", rep(c("B", "W"), each = n/2))
net3 Network attributes:
vertices = 250
directed = FALSE
hyper = FALSE
loops = FALSE
multiple = FALSE
bipartite = FALSE
total edges= 0
missing edges= 0
non-missing edges= 0
Vertex attribute names:
race vertex.names
No edge attributesform.formula.3 <- ~edges + nodematch("race") + degree(0) + concurrent
target.stats.3 <- c(0.9*n/2, (0.9*n/2)*(5/6), 0.36*n, 0.18*n)How did we get those expressions? Why don’t we specify degree(1) as well?
Now we turn to dissolution. This is complicated slightly by the fact that our dissolution probabilities differ by the race composition of the members. One dissolution formula for representing this is:
diss.formula.3 <- ~offset(edges) + offset(nodematch("race"))And fortunately, dissolution_coef is able to handle this model, as one can see by visiting its help page:
?dissolution_coefsWe also see there that it expects us to pass our durations in the order [mean edge duration of non-matched dyads, mean edge duration of matched dyads]. For us this means c(200, 100).
17.4.2 Model Fitting
Putting this together:
fit3 <- netest(net3,
formation = form.formula.3,
target.stats = target.stats.3,
coef.diss = dissolution_coefs(~offset(edges) + offset(nodematch("race")),
c(200, 100)))17.4.3 Model Simulation
And simulate:
sim3 <- netdx(fit3, nsteps = 1000, nsims = 10, keep.tedgelist = TRUE)
Network Diagnostics
-----------------------
- Simulating 10 networks
|**********|
- Calculating formation statisticsWe query the object as before to see if it worked:
sim3EpiModel Network Diagnostics
=======================
Diagnostic Method: Dynamic
Simulations: 10
Time Steps per Sim: 1000
Formation Diagnostics
-----------------------
Target Sim Mean Pct Diff Sim SE Z Score SD(Sim Means)
edges 112.50 113.622 0.997 1.006 1.115 3.860
nodematch.race 93.75 94.342 0.631 0.892 0.663 3.244
degree0 90.00 89.032 -1.075 0.728 -1.328 3.083
concurrent 45.00 45.771 1.714 0.746 1.033 2.876
SD(Statistic)
edges 9.311
nodematch.race 8.646
degree0 8.760
concurrent 7.388
Duration Diagnostics
-----------------------
Target Sim Mean Pct Diff Sim SE Z Score SD(Sim Means)
edges 200 205.626 2.813 6.079 0.925 21.011
nodematch.race 100 99.791 -0.209 1.097 -0.190 6.276
SD(Statistic)
edges 44.656
nodematch.race 10.595
Dissolution Diagnostics
-----------------------
Target Sim Mean Pct Diff Sim SE Z Score SD(Sim Means)
edges 0.005 0.005 -5.244 0 -1.617 0
nodematch.race 0.010 0.010 1.140 0 1.100 0
SD(Statistic)
edges 0.016
nodematch.race 0.010Alas, we see that for now the functionality does not disaggregate the different kinds of partnerships for the duration. Let’s try the plots instead:
plot(sim3, type = "formation")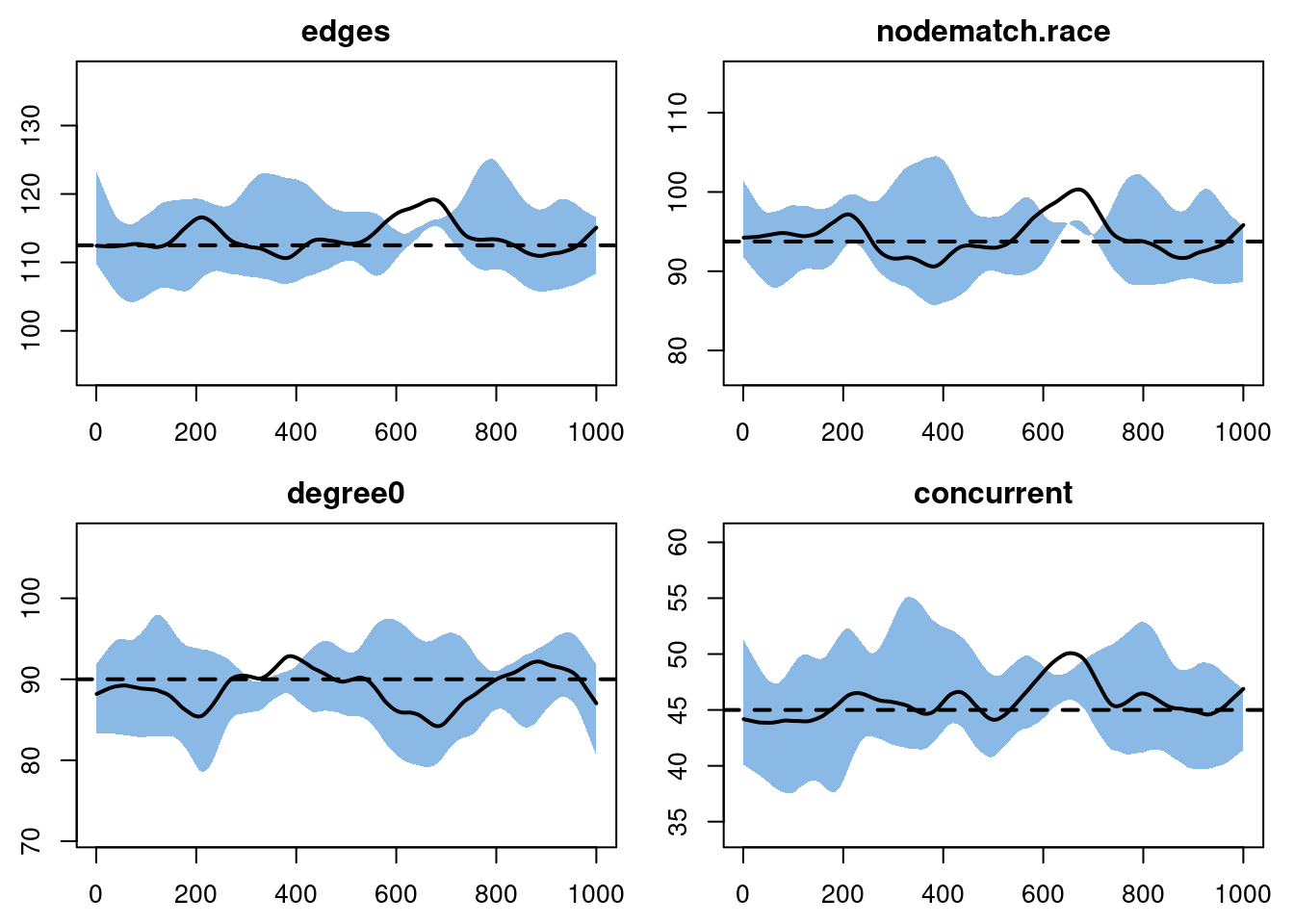
Nice.
plot(sim3, type = "duration")Error: Duration plots for heterogeneous dissolution models not currently available Still no luck. This is not available as an automatic feature, so instead we will need to do this by hand. In order to minimize censoring, let us look at the final duration of all relationships that began within the first 100 time steps of the simulation, and divide these by race composition:
race <- get_vertex_attribute(net3, "race")
tel3 <- as.data.frame(sim3, sim = 1)
mean(tel3$duration[(race[tel3$tail] != race[tel3$head]) & tel3$onset < 100])[1] 199.3636mean(tel3$duration[(race[tel3$tail] == race[tel3$head]) & tel3$onset < 100])[1] 88.39796The model appears to be accurately separating out race-homogeneous and race-heterogeneous ties for different dissolution probabilities, all while maintaining the correct cross-sectional structure.
17.5 Scenario 4: Full STERGM
Now let us imagine that our relationship durations are much shorter; we repeat the last model, but instead this time have 10 and 20 timesteps.
You might think that we simply need to change the code to reflect these new durations:
fit4 <- netest(net3,
formation = form.formula.3,
target.stats = target.stats.3,
coef.diss = dissolution_coefs(~offset(edges)+offset(nodematch("race")),
c(20, 10)))But notice what happens when we simulate:
Did we hit the target statistics?
sim4 <- netdx(fit4, nsteps = 1000, nsims = 10, keep.tedgelist = TRUE)
Network Diagnostics
-----------------------
- Simulating 10 networks
|**********|
- Calculating formation statisticsplot(sim4, type = "formation")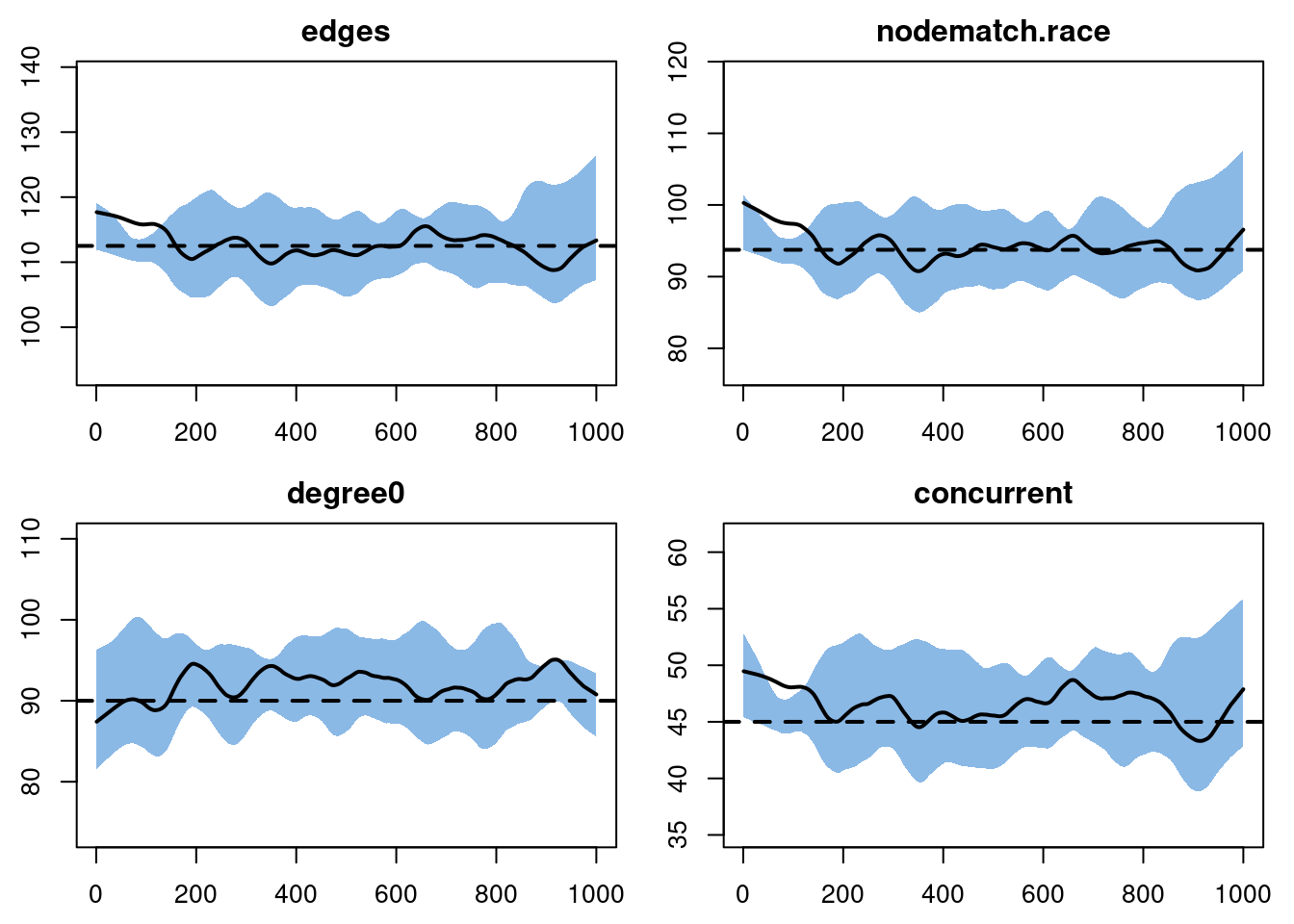
The number of edges might seem too low by just a little bit, although it’s hard to say for sure. More clearly, though, the value for degree 0 is consistently too high. The amount is small, but the consistency of it suggests that something is off with the model. If you simulated out for a longer period of time, you would see this consistency continue.
This is because, unbeknownst to you, we have until now not really been fitting a STERGM model. It turns out that when relational durations are short (perhaps less than 25-50 time steps or so), STERGM estimation is generally efficient and stable. When they are long, however, this is not the case; estimation can be slow (perhaps several hours) and unstable. We can get a sense for why if we think about the basic algorithm for model estimation in a STERGM:
- Begin with an initial guess at the model coefficients
- Simulate multiple time steps using these
- Compare both the cross-sectional structure and the pattern of change between adjacent time steps to the expectations for these
- Update the coefficients accordingly
- Repeat Steps 2-4 until some criterion of convergence is achieved.
The problem for this case is that, when relationships are very long, the expected amount of change from one time step to the next is almost 0. That makes estimation for such a model both unstable and slow.
The good news is that Carnegie et al. (2014) demonstrate that one can approximate the coefficients of a formation model in a STERGM with a much simpler call to an ERGM, in the case where all of the terms in the dissolution model are also in the formation model. Moreover, this approximation works best in precisely those cases when precise MLE estimation is most difficult—when relationship durations are long. And for relationships on the order of 50 times steps or more, it generally works so well that the means of the simulated statistics from the model are indistinguishable from the target stats, as we saw in the previous three cases. Because of this, using the approximation is the default behavior in EpiModel.
In this case, however, we can readily see some imprecision in the approximation. This is just one of many reasons why it is critical to always check model diagnostics. Here, we see that want to move to a full estimation; to do so, we need to add in the flag edapprox.
Note: for now, we also need to add in two control arguments that are not particularly intuitive; these relate to a change in the most recent version of tergm in just the last few weeks, and will likely not be needed after the next update that makes a small change to the defaults. If you leave these control arguments out, the model will still fit fine, it will just take longer.
fit5 <- netest(net3,
formation = form.formula.3,
target.stats = target.stats.3,
coef.diss = dissolution_coefs(~offset(edges) + offset(nodematch("race")),
c(20, 10)),
set.control.tergm = control.tergm(SA.max.interval = NA,
SA.min.interval = NA),
edapprox = FALSE)Now we want to see if we hit the target statistics.
Note: there is also another very short-term mismatch introduced by the very recent enhancements in tergm that lead will require some small tweaks inside EpiModel. In the meantime, a quick workaround is:
fit5$target.stats.names <- substring(fit5$target.stats.names, 6) OK, back to our regularly scheduled programming:
sim5 <- netdx(fit5, nsteps = 1000, nsims = 10, keep.tedgelist = TRUE)
Network Diagnostics
-----------------------
- Simulating 10 networks
|**********|
- Calculating formation statisticsplot(sim5, type = "formation")
Much better. And how about duration?
race <- get_vertex_attribute(net3, "race")
tel5 <- as.data.frame(sim5, sim = 1)
mean(tel5$duration[(race[tel5$tail] != race[tel5$head]) & tel5$onset < 100])[1] 19.86207mean(tel5$duration[(race[tel5$tail] == race[tel5$head]) & tel5$onset < 100])[1] 9.87583617.6 References
Carter T. Butts, Ayn Leslie-Cook, Pavel N. Krivitsky, and Skye Bender-deMoll.
networkDynamic: Dynamic Extensions for Network Objects. The Statnet Project http://www.statnet.org, 2013. R package version 0.6. http://CRAN.R-project.org/package=networkDynamicKrivitsky, P.N., Handcock, M.S,(2014). A separable model for dynamic networks JRSS Series B-Statistical Methodology, 76 (1):29-46; 10.1111/rssb.12014 JAN 2014.
Pavel N. Krivitsky. Modeling of Dynamic Networks based on Egocentric Data with Durational Information. Pennsylvania State University Department of Statistics, 2012(2012-01). http://stat.psu.edu/research/technical-reports/2012-technical-reports
Pavel N. Krivitsky and Mark S. Handcock.
tergm: Fit, Simulate and Diagnose Models for Network Evoluation based on Exponential-Family Random Graph Models. The Statnet Project http://www.statnet.org, 2013. R package version 3.1-0. http://CRAN.R-project.org/package=tergm.